Over the weekend my daughter texted me a screenshot. She had googled my name to see what came up, and an AI summary handed her a tidy paragraph: Indianapolis-based entrepreneur, author, executive AI advisor, founder of LaunchReady. "This makes you sound so cool," she wrote. It had drawn that summary from my LinkedIn, our website, a profile in the Indianapolis Business Journal, and a few other places, and it stated every word with total confidence.
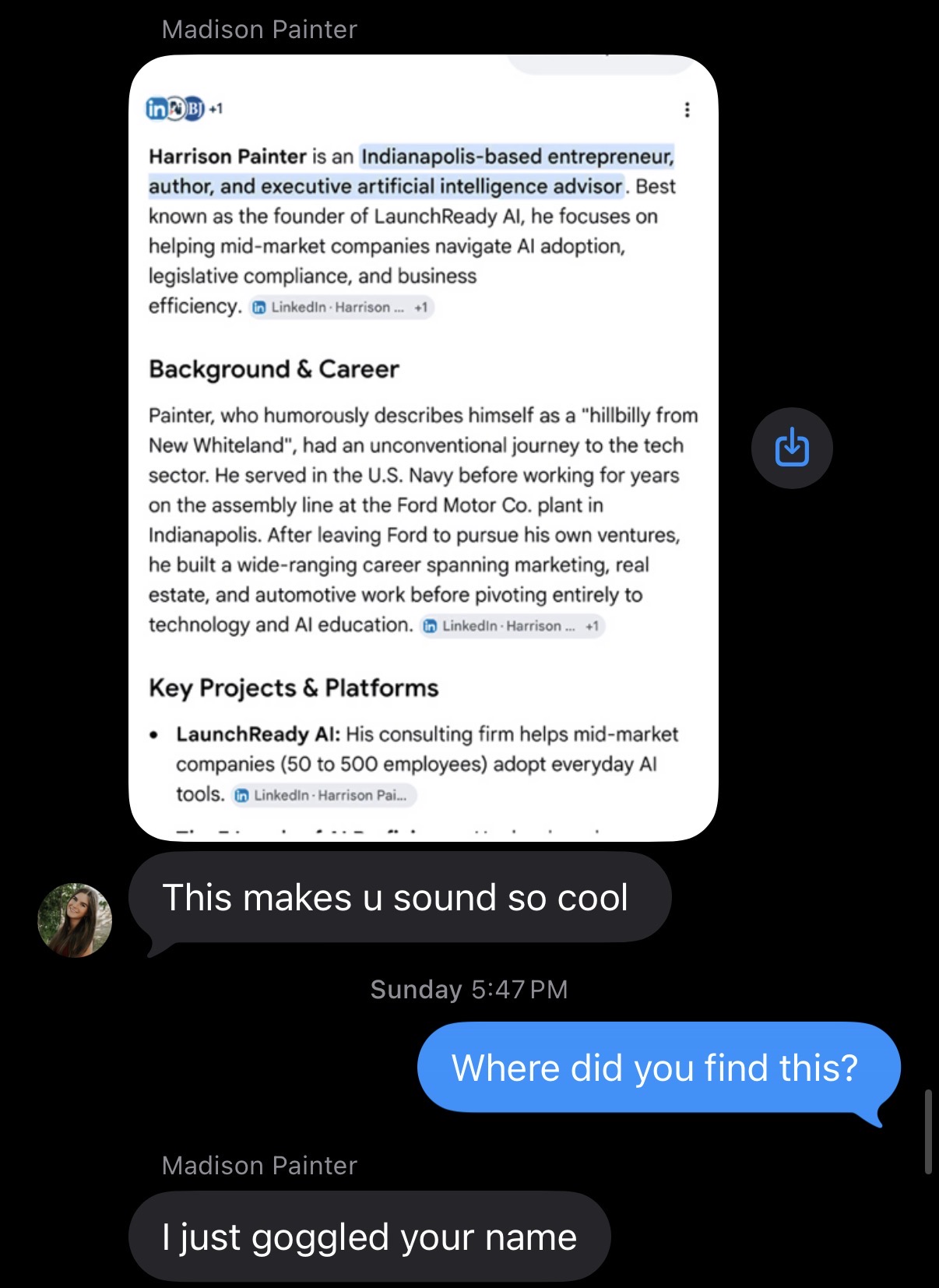
This time, the AI was right. It described me accurately. But if it had been wrong, it would have said so with the same confidence, and she would have had no way to tell. Neither would anyone else.
That is the risk underneath everything we are all doing with AI right now. You ask it for something, a statistic for the board deck, a summary of a report you did not have time to read, a clean paragraph for a client email, and it comes back in seconds, polished and certain. It does not say "I think." It does not say "double-check this one." It never hesitates.
That missing hesitation is what should make you slow down. Once you paste the answer in, it is yours. Your name is on the deck. AI does not sit in the room when the number turns out to be wrong. You do.
The tool is usually brilliant. The trouble is that it is brilliant and certain at the same time, and certainty is contagious. A confident answer makes you feel finished, and feeling finished is exactly what stops you from checking.
We got a close look at this on ourselves this week.
What the engine caught
We run an agentic content engine. A powerful one. It scans the day's AI news, researches the stories worth sharing, checks the facts, scores them, and drafts the articles and briefings we publish, and it runs most of that on its own before a person ever enters the office. Every piece you read from us comes off that autonomous production line. We build each one to rank in search and get cited by the AI answer engines, for an audience we mapped before a word gets written.
None of this is hands-off, and that is the entire point. Think of the engine as a tireless team of researchers and writers that does the legwork faster than any person could. But a team like that still needs an editor, and that job does not automate. A person reads every draft, shapes the angle, rewrites what does not sound like our voice, and verifies the sources before the piece earns the LaunchReady seal of approval. We put real human time into everything we do. The engine does the heavy lifting; the editor does the judging, and the buck stops at that desk.
For a long time, that setup worked beautifully. Then the work started to slip, and it started small. A stat that was a little out of date. A number we could not quite source. Easy to fix, easy to wave off as a one-off. But the catches kept coming, and they kept getting bigger. In the space of a couple of weeks, what we had shrugged off as an acceptable error rate was turning catastrophic. Small misses do not stay small. They compound.
The one that finally made us stop came in looking finished. Clean writing, the right shape, ready to send. It was not ready. It leaned on facts that had gone stale and on numbers we had not been able to trace back to a real source. Nothing dramatic, just the ordinary kind of "probably fine" that walks out the door when you have a lot to do and the draft looks good.
The check at the end caught it, so we held it. Better a day late than wrong with the LaunchReady name on it. But by then the real problem was clear. One draft is easy to hold. The trend underneath all of them was the thing we had to fix. So we spent the next stretch making sure these catches were not luck. A save you cannot repeat is just a near miss with a happy ending.
The risk lives in the confidence
That day taught us something that travels well past our own content engine.
A wrong answer, you can catch. The one that gets you is the confident answer you never thought to question, because it arrived sounding exactly as sure as the right ones. AI delivers a shaky guess and a rock-solid fact in the same steady voice. It will never flag the difference for you.
So the hesitation has to come from somewhere else. It comes from you, and from the habits you build around the workflow. That is the real game now. Speed is the easy half; the tools hand it to you for almost free. Trust is the half you have to build with purpose.
The models are getting better at this
We have a stake in saying so. Part of why we rebuilt this engine in the first place was to put it on the newest Claude model, Opus 4.8, and see for ourselves how much better the new generation really was. In our own testing so far, it has held up well. The companies building these tools are pushing hard on exactly this problem. Anthropic put honesty near the center of this release, and its early testers report the model is "more likely to flag uncertainties about its work and less likely to make unsupported claims." That is real, and it helps.
Read the fine print, though. Anthropic itself calls the change "a modest but tangible improvement," and the gain comes largely from the model telling you when it is unsure rather than from never being wrong. You still have to hear the flag and act on it. And on the independent benchmarks, the strongest models in mid-2026 still introduce unsupported claims a few percent of the time even when summarizing a document they were handed, with weaker ones far more often (Vectara's hallucination leaderboard, May 2026). A few percent, with your name on it, is not zero.
Even the strongest models in mid-2026 still introduce unsupported claims a few percent of the time when summarizing a document they were handed. A few percent, with your name on it, is not zero.
Source: Vectara Hallucination Leaderboard, May 2026It is genuinely better. It is not yet something you can trust at face value, and the habit is what carries you across that distance.
What building it on purpose looks like
We turned our near miss into four habits. None of them need an engine. You can run all four by hand on your next AI-assisted task.
We taught the system to check the age of what it leans on, because AI is happy to hand you last year's number in this morning's voice. We taught it to notice when it is repeating something already said, instead of dressing up a recycled take as a fresh one. We made it prove every number against a real, findable source before the work can move forward, and stop cold when a figure cannot be traced. And we kept a person on the send button, because the engine can run the whole line on its own, but a human still decides what carries our name.
The result is a process that is slower on purpose at the exact moments where speed would cost us trust. That trade felt obvious the second we named it.
The temptation runs the other way. Point the engine at the open web, take the human out, and wake up to ten polished articles a day. You might get away with it for a while. But it is a losing strategy. The internet is already drowning in confident, unchecked AI writing, and piling on more of it faster only makes you part of the flood of AI slop. The hard human work is what makes anything we publish worth a reader's trust.
The whole line looks like this.
We did not build this so you would hire us to run your content. We built it because the discipline behind it is the thing worth having, and that part is yours to keep whether we ever talk or not. And if you want to build your own, we are happy to walk you through it.
Agents drift, the same as people do
The guardrails help. They do not finish the job.
What we ran into is older than AI. Anyone who has managed people knows the pattern. A team that was on top of its game gets comfortable. The work still ships, so no alarm goes off, but the edges go soft. People get busy. People get distracted. Think about how many people on any team quietly work around the policy they were handed. Agents are no different. They drift the same way, they work around their own guardrails the same way, and a check can always miss or a rule can be drawn too narrow.
So the guardrails lower the odds. They do not remove the need for someone to watch. There is no magic button here, and the overseeing never moves off a human's desk. Handing the work to AI does not retire you as its manager. The job is never done, and that is exactly what a leader is for.
The skills underneath the habits
Strip those four habits down and they are not really software. They are three human skills, and they have names in The 7 Levels of AI Proficiency, our measurable model for how a person grows with AI.
The first is critical thinking: the discipline to question a confident answer and trace a claim before you lean on it. The Critical Thinker is the one who notices when a clean draft is sitting on a thin source.
The second is building the system: turning a single good catch into a habit that holds every time, so nobody has to get lucky twice. The Builder makes the lesson permanent.
The third is orchestrating the whole thing: arranging the tools, the checks, and the human judgment so each does what it is best at. The Orchestrator keeps a person in the seat that judgment requires.
You do not need our engine to practice any of this. You need the instinct to doubt the confident answer, the discipline to turn a lesson into a habit, and the judgment to stay in the loop where it counts.
Your rep this week
Skill comes from doing reps, not from reading about them. Try this one. It is the same discipline that held this piece.
-
Pick one AI answer you are about to use.
A statistic, a quote, a "studies show" line from any tool. Just one, the next one you reach for.
-
Trace it to where it actually came from.
Not the tool's summary of it. The original report, page, or study behind the number.
-
Decide if it holds.
Found the source and it says what you thought? Use it, and feel the difference in how it holds up when someone asks. Could not find it? That is the rep working. Leave it out.
One claim, traced on purpose. Do that once this week and you have practiced the exact habit that stands between a confident answer and your name on it.
One more thing
There are two kinds of professionals forming around AI right now. One forwards the confident answer because it looked finished. The other pauses, checks the one thing that would be embarrassing to get wrong, and sends it knowing. The tools are the same for both. The habit is the only difference, and the habit is learnable.
We would rather be a day late than publish something we have not checked. That is the standard we hold ourselves to, and it is the same standard worth holding your own work to.
If you are wondering where you sit on all of this, that is the right question, and The 7 Levels of AI Proficiency is built to answer it. You can find your own level in about ten minutes. Wherever you are, the next step is the same as ours this week: run one verification rep, then turn what you learn into a habit you keep.
Sources
- LaunchReady, FranklinCovey's hands-off managers and the AI readiness lesson
- LaunchReady, Gallup, the AI elite, and the layoff line
- LaunchReady, Clinicians, AI, and the deskilling worry
- The 7 Levels of AI Proficiency assessment
- The 7 Levels of AI Proficiency framework
- Anthropic, Introducing Claude Opus 4.8
- Vectara Hallucination Leaderboard (HHEM)
Frequently Asked Questions
Why is AI being confident a problem if the answers are usually good?
Confidence and accuracy are two different things, and AI shows you only the confidence. It delivers a shaky guess and a verified fact in the identical sure voice, and it never flags which is which. The real risk is the confident answer you never thought to question, the one that arrived before your name went on it.
How do I check an AI answer without slowing everything down?
Start with one claim per task, the single figure or fact that would be costly to get wrong, and trace it to its original source rather than the tool's summary. It takes a minute and it builds a habit. You are not re-verifying everything; you are catching the one thing most likely to cost you before it ships.
What did LaunchReady actually change in its content engine?
Four habits: it checks the age of source material and refuses stale inputs without human clearance, it flags when it is repeating something already published, it requires every number to trace to a findable source before the work advances, and it keeps a person making the final call on what publishes. The engine drafts and checks; it does not publish on its own.
How does this connect to The 7 Levels of AI Proficiency?
The habits above are really three human skills: critical thinking (question and verify a confident answer), building the system (turn a good catch into a habit that holds), and orchestrating the parts (keep human judgment in the loop). Those map to defined stages in the framework, which measures how a person and a team grow with AI from first awareness to full orchestration.
Isn't AI getting more accurate? Why still check?
Yes, and the newest models are better at flagging when they are unsure. Anthropic calls its Opus 4.8 release a "modest but tangible improvement." But the strongest models still introduce unsupported claims a few percent of the time even when summarizing a document they were handed (Vectara, May 2026), and a few percent with your name on it is not zero. Improving accuracy lowers the odds; it does not remove your responsibility for what ships under your name.
What is the one thing I should do this week?
Pick a single AI answer you are about to use, trace it to its original source instead of trusting the summary, and decide whether it holds. One verification rep, done on purpose, is how the habit starts.

Find your AI Proficiency level
The free 7 Levels assessment places you across seven stages of AI capability. Under ten minutes. Research-backed scoring.